打开单篇论文网址,发现论文由pdf.js加载,但是原生的下载按钮被隐藏了,这个好解决
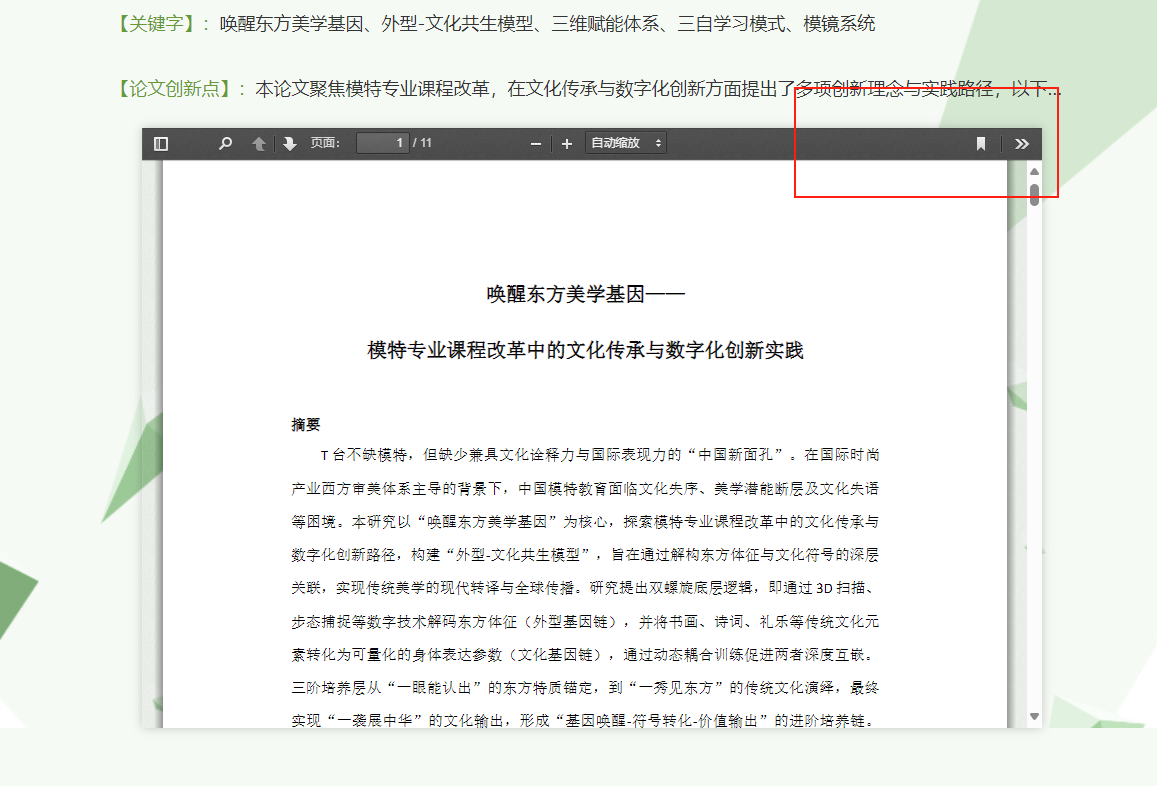
打开f12审查元素,找到<button id="download" class="toolbarButton download hiddenMediumView" style="display:none;" title="下载" tabindex="34" data-l10n-id="download"> <span data-l10n-id="download_label">下载</span></button>把style="display:none;"注释掉即可显示下载按钮。如果不喜欢这个方法,在“网络”里用筛选器筛选出.pdf后缀文件,也一样能下载。
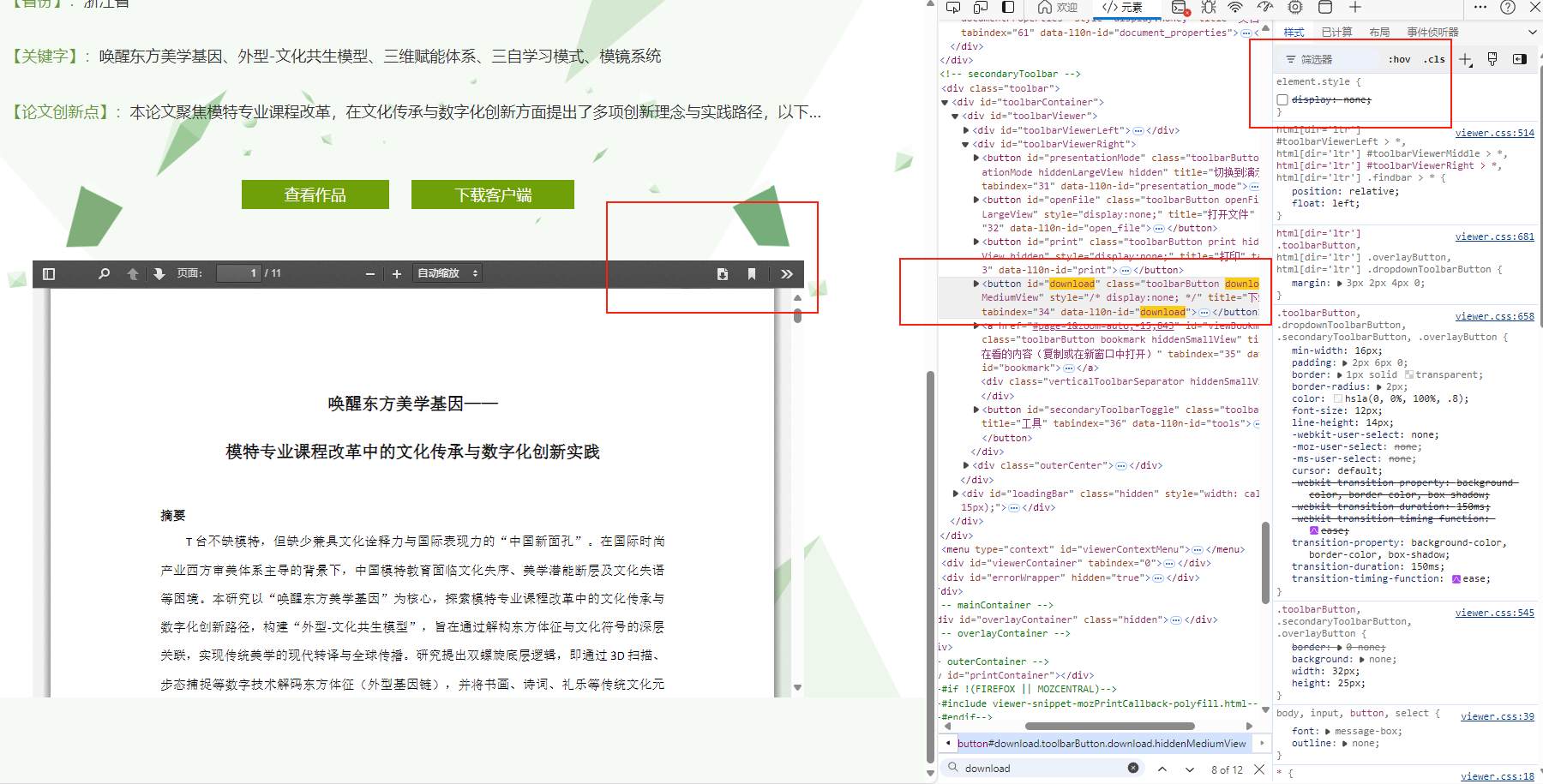
但是这样太麻烦了,每次点开链接,再点击“查看作品”,pdf才会出现,再审查元素,前后30秒才能下载单篇,有没有可以批量下载的方法?
一般移动端浏览器查看pdf文件,前端兼容性会比较好(简陋),果然,分析移动端网址,发现打开后直接就是pdf.js在加载pdf。而且网址好简单哈哈哈哈吼吼吼,直接用论文编号(productid)就可以打开文件,那只要批量输入ID,岂不是很容易实现批量下载?!
于是CTRL+U查看网页源代码:
<!DOCTYPE html>
<script type="text/javascript" src="/activity/resources/js/jquery.js"></script>
<html dir="ltr" mozdisallowselectionprint moznomarginboxes>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1">
<!--#if GENERIC || CHROME-->
<meta name="google" content="notranslate">
<!--#endif-->
<title>人工智能引领教育教学变革的探究</title>
<link rel="stylesheet" href="/activity/H5/subjectResources/pdf/web/viewer.css"/>
<!--#if !PRODUCTION-->
<link rel="resource" type="application/l10n" href="locale/locale.properties"/>
<!--#endif-->
<!--#if !PRODUCTION-->
</head>
<body >
<div style=" height: 100%;">
<iframe frameborder="0" name="Iframe1" src="https://media.andedu.net/andedu/plugins/pdf.js/web/viewer.html?docurl=aHR0cHM6Ly9kbWVkaWEuYW5kZWR1Lm5ldC8yMDI1MDgwMTIwMzEvNWEyYWUwMDZhOTRmNDIzMjM4MTk1YWVjNDMzYzYwNmUvcHJvZHVjdC9jcF9saWFvbmluZy9ET0NVTUVOVC8yNTA3MjgvTC05MDQ2ODEzMS0wLTBDMDMyMTc0NUQvNTg4MDc4OS5wZGY=" width="100%" height="100%"></iframe>
</div>
</body>
</html>发现源代码里的PDF链接是嵌入在iframe的src属性中:
<iframe frameborder="0" name="Iframe1" src="https://media.andedu.net/andedu/plugins/pdf.js/web/viewer.html?docurl=aHR0cHM6Ly9kbWVkaWEuYW5kZWR1Lm5ldC8yMDI1MDgwMTE4MDgvZjYwMmIzYzc5ODg5Y2RhMTAxZjUyODAzYjg2NmM0ZDkvcHJvZHVjdC9jcF9saWFvbmluZy9ET0NVTUVOVC8yNTA3MjgvTC05MDQ2ODEzMS0wLTBDMDMyMTc0NUQvNTg4MDc4OS5wZGY=" width="100%" height="100%"></iframe>URL参数用Base64编码,想到python的base64库很容易实现编码解码,还有内置的HTTP请求库urllib可以基本实现批量下载功能。
第一波简单写了小DEMO后发现报错“urllib3.exceptions.SSLError: [SSL: UNSAFE_LEGACY_RENEGOTIATION_DISABLED] unsafe legacy renegotiation disabled (_ssl.c:1020)”
发现是SSL安全校验出现问题,可能是Python 3.13版本太严格了?降级可太麻烦,于是采用urllib禁止警告,就可以正常请求了:
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
完整代码拆解如下:
1.导入必要的库和模块
import urllib.request
import base64
import re
from bs4 import BeautifulSoup
import ssl
import urllib3
import time
import os
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)2.定义下载函数,忽略SSL安全认证,并启用不安全的遗留重新协商(因为之前SSL报错)
def download_pdf(product_id):
try:
context = ssl._create_unverified_context()
context.options |= 0x00040000 # OP_ALLOW_UNSAFE_LEGACY_RENEGOTIATION
url = f"https://edu.10086.cn/activity/activity/thesis/h5SeePDF?productId={product_id}"
print(f"正在处理产品ID: {product_id}")3.创建一个HTTP请求,设置User-Agent头,然后发送请求并获取响应,读取内容后解码为UTF-8文本
req = urllib.request.Request(
url,
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
)
response = urllib.request.urlopen(req, context=context, timeout=30)
html_content = response.read().decode('utf-8')4.使用BeautifulSoup解析HTML,查找iframe标签提取src:https://media.andedu.net/andedu/plugins/pdf.js/web/viewer.html?docurl=aHR0cHM6Ly9kbWVkaWEuYW5kZWR1Lm5ldC8yMDI1MDgwMTIwMzEvNWEyYWUwMDZhOTRmNDIzMjM4MTk1YWVjNDMzYzYwNmUvcHJvZHVjdC9jcF9saWFvbmluZy9ET0NVTUVOVC8yNTA3MjgvTC05MDQ2ODEzMS0wLTBDMDMyMTc0NUQvNTg4MDc4OS5wZGY=,再用正则表达式提取docurl参数的值;'aHR0cHM6Ly9kbWVkaWEuYW5kZWR1Lm5ldC8yMDI1MDgwMTIwMzEvNWEyYWUwMDZhOTRmNDIzMjM4MTk1YWVjNDMzYzYwNmUvcHJvZHVjdC9jcF9saWFvbmluZy9ET0NVTUVOVC8yNTA3MjgvTC05MDQ2ODEzMS0wLTBDMDMyMTc0NUQvNTg4MDc4OS5wZGY=',最后解码得到PDF下载链接
soup = BeautifulSoup(html_content, 'html.parser')
iframe = soup.find('iframe')
if iframe and 'src' in iframe.attrs:
iframe_src = iframe['src']
match = re.search(r'docurl=([^&]+)', iframe_src)
if match:
encoded_url = match.group(1)
actual_url = base64.b64decode(encoded_url).decode('utf-8')
print(f"解码后的PDF URL: {actual_url}")5.创建新HTTP请求来访问实际url,响应状态码200就创建下载目录,从url提取文件名+产品Id(论文编号),方便后续核对。然后然后以二进制模式打开文件并写入内容。
pdf_req = urllib.request.Request(
actual_url,
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
)
pdf_response = urllib.request.urlopen(pdf_req, context=context, timeout=30)
if pdf_response.status == 200:
download_dir = "downloaded_pdfs"
if not os.path.exists(download_dir):
os.makedirs(download_dir)
original_filename = actual_url.split('/')[-1]
filename = f"{product_id}_{original_filename}"
file_path = os.path.join(download_dir, filename)
with open(file_path, 'wb') as f:
f.write(pdf_response.read())
print(f"PDF已成功下载为: {file_path}")
return True6.错误处理
else:
print(f"下载失败,状态码: {pdf_response.status}")
else:
print(f"产品ID {product_id}: 未找到docurl参数")
else:
print(f"产品ID {product_id}: 未找到iframe标签")
except Exception as e:
print(f"处理产品ID {product_id} 时出错: {str(e)}")
return False7.主函数提示用户输入多个产品ID,每行一个(因为我的ocr识别自动换行),输入空行或"end"表示结束输入。还要设置下载间隔时间,避免请求频繁导致被服务器封锁(虽然我也不知道什么时候会被封锁),然后批量下载。
def main():
print("PDF批量下载工具 - 中国移动教育论文")
print("=" * 50)
print("\n请输入多个产品ID,每行一个。输入完成后输入一个空行或输入'end'表示结束:")
product_ids = []
while True:
line = input()
if not line.strip() or line.strip().lower() == 'end':
break
if line.strip():
product_ids.append(line.strip())
if not product_ids:
print("没有有效的产品ID!")
return
print(f"共找到 {len(product_ids)} 个产品ID,开始下载...")
delay = input("请设置下载间隔秒数 (推荐2-5秒,避免请求过于频繁): ")
try:
delay = float(delay)
except:
delay = 3.0
success_count = 0
fail_count = 0
for i, product_id in enumerate(product_ids):
print(f"\n[{i+1}/{len(product_ids)}] 处理产品ID: {product_id}")
if download_pdf(product_id):
success_count += 1
else:
fail_count += 1
if i < len(product_ids) - 1:
print(f"等待 {delay} 秒后继续下一个下载...")
time.sleep(delay)
print(f"\n批量下载完成! 成功: {success_count}, 失败: {fail_count}")
if __name__ == "__main__":
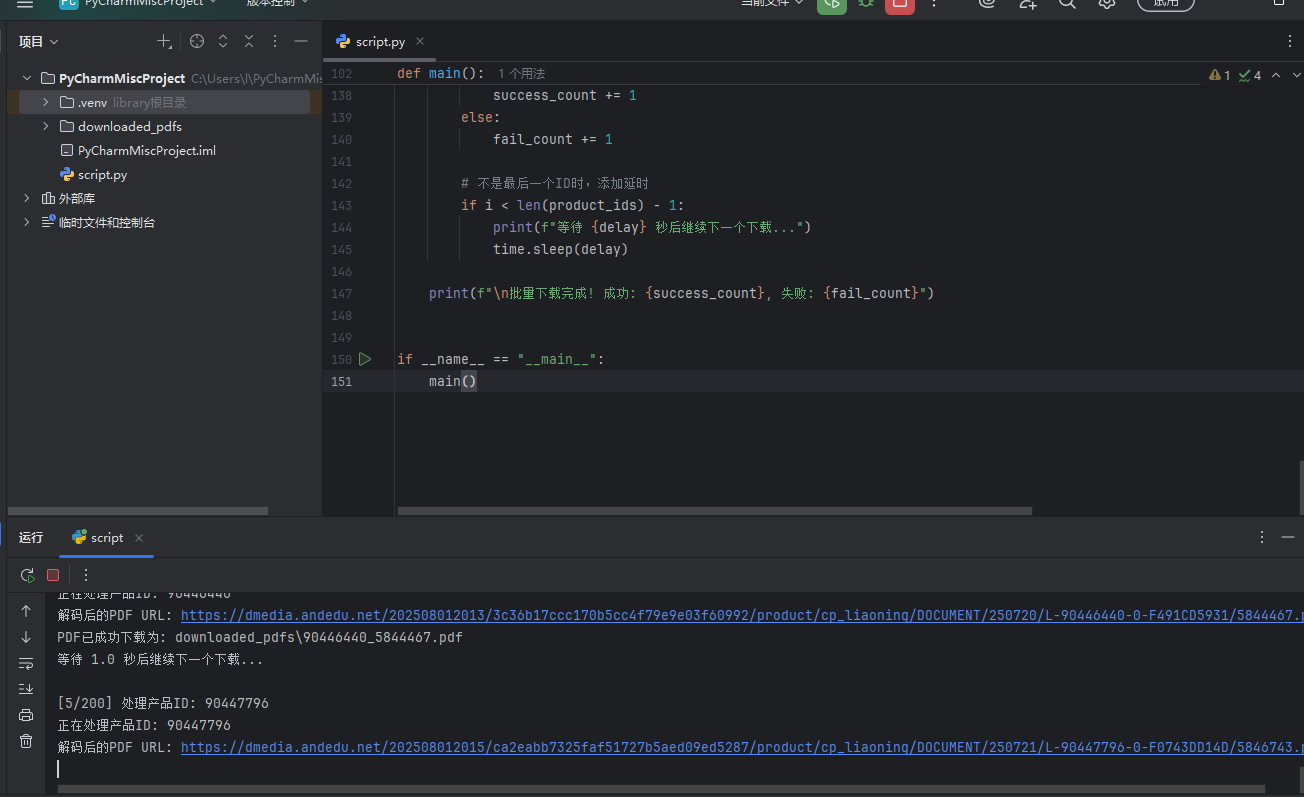
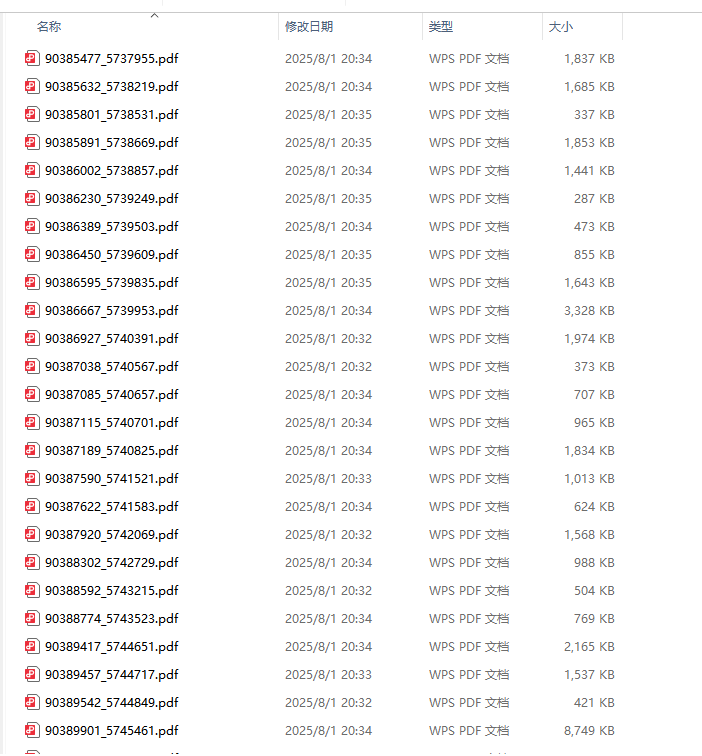
main()最终效果:
Comments NOTHING